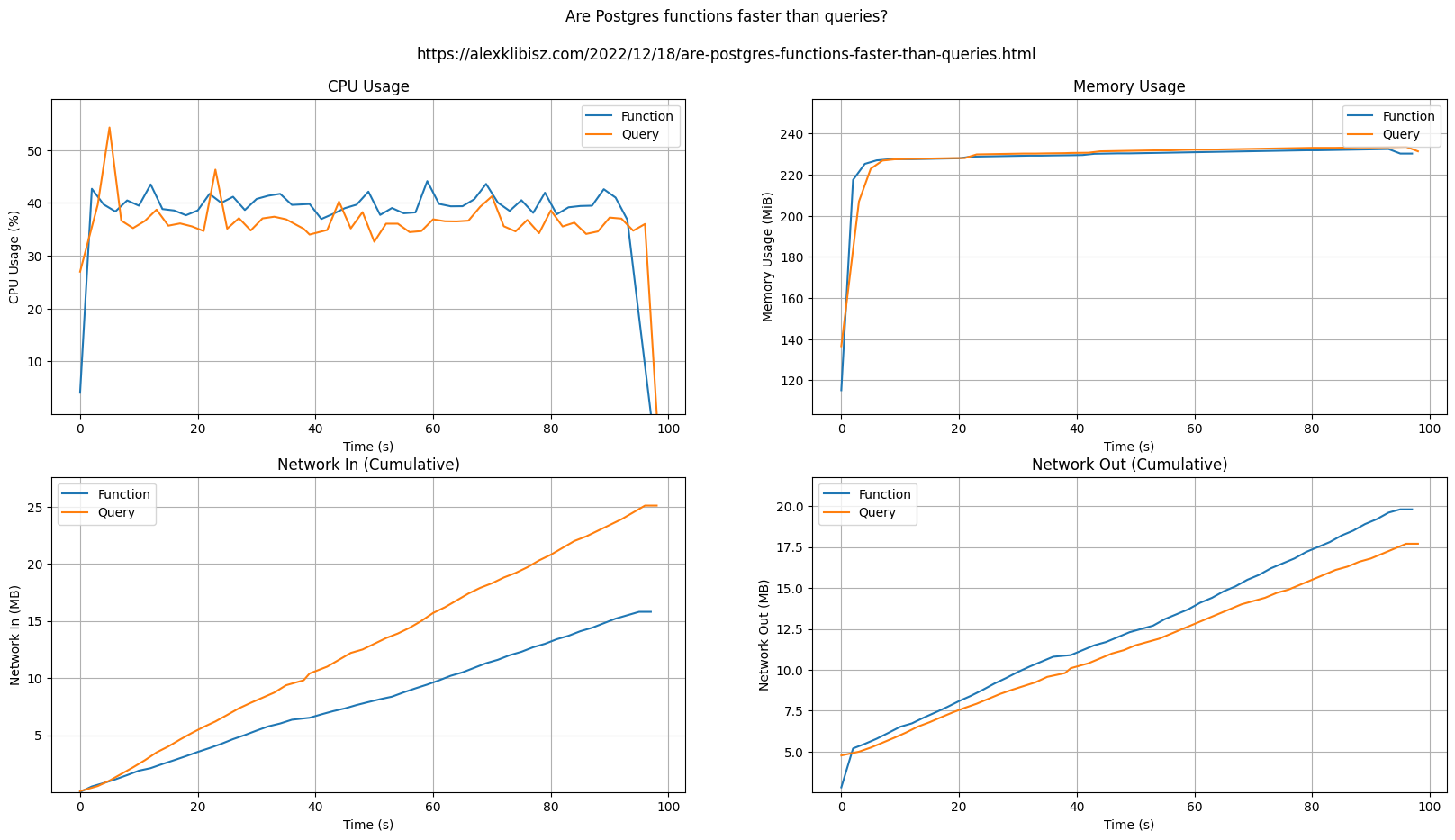
Introduction
In this post, we’ll implement and optimize a text search system based on Postgres Trigrams.
We’ll start with some fundamental concepts, then define a test environment based on a dataset of 8.9 million Amazon reviews, then cover three possible optimizations.
Our search will start very slow, about 360 seconds.
With some thoughtful optimization we’ll end up at just over 100 milliseconds – a ~3600x speedup!
These optimizations won’t apply perfectly to every text search use-case, but they should at the very least spark some ideas.
Defining “text search”
For our purposes, “text search” is defined as follows:
- We have a database table with multiple text columns.
- A user provides one input: a query string (think Google or Amazon search box).
- We search for ten rows in our table for which at least one of the columns matches the query string. A match can be either exact or fuzzy. For example, the query string “foobar” is an exact match for the value “foobarbaz” and a fuzzy match for the value “foo bar”.
- Once we’ve found ten such rows, we score them, re-rank them by their scores, and return them to the user.
Why Postgres?
Postgres is a ubiquitous relational database, but dedicated search systems like Solr, Elasticsearch, and Opensearch are far better-known for text search.
Still, Postgres offers some competent text search functionality, with several benefits over a dedicated search system:
- We avoid operating additional infrastructure (e.g., an Elasticsearch cluster).
- We avoid syncing data between systems (e.g., Postgres to Elasticsearch).
- We avoid re-implementing non-trivial features (e.g., multi-tenant authorization).
Having implemented and operated search functionality on both Postgres and Elasticsearch, my current heuristics for choosing between them are:
- If search is our core offering, or we can’t afford to fit our searchable text in Postgres’ shared memory buffer, use Elasticsearch and earmark one engineer for operations and tuning.
- Otherwise, Postgres is probably good enough. At the very least, we’ll end up with a competent baseline for further improvement.
As a case-study, Gitlab has publicly documented their journey in growing from Postgres trigram-based search to advanced search in Elasticsearch.
What are Trigrams?
A trigram is simply a three-character sequence from a string.
For example, the trigrams in "hello" are {" h"," he","hel","ell","llo","lo "}.
Trigrams present a simple solution for string comparison: to compare two strings, we can count the number of trigrams they share.
For example, “hello” and “helo” share 4 trigrams. “hello” and “bye” share 0. This isn’t fool-proof: “hello” shares more trigrams with “jello” than with “hi”. But it’s usually a strong baseline.
Why not Full Text Search?
Postgres also offers Full Text Search.
I’m personally more familiar with trigram-based search, which is part of the reason we’ll use trigrams in this post.
From some experimenting with Full Text Search, I’ve found the API focuses more narrowly on natural language text (i.e., words, spaces, punctuation), than on general-purpose text (i.e., natural language text and product SKUs and email addresses, …).
Still, some optimizations in this post might translate nicely to Full Text Search.
The Test Environment
The full test environment is available on Github.
Let’s have a look at some specific components.
Host
Everything is running on my Dell XPS-9570 Laptop with an Intel i7-8750H, 32GB of memory, an SSD, and Ubuntu 20.04.
Exact timing will vary by the host environment, but the relative performance should be host-agnostic.
Postgres
We’ll use Postgres version 14.1.0, running the bitnami/postgresql:14.1.0 container.
All examples should work on Postgres >= 13.
We’ll set two server configurations:
# Provide 4GB of memory for buffers.
# This lets us keep the full table and indexes in memory.
shared_buffers = 4096MB
# Set to true so that `explain (... buffers ...) will include IO timings.
track_io_timing = true
We’ll also set two query planning configurations:
-- This disables parallel gathers, as I've found they produce highly
-- variable results depending on the host system.
set max_parallel_workers_per_gather = 0;
-- This makes it more likely that the query planner chooses an index scan
-- instead of another strategy. I've found this will generally improve
-- performance on any system with an SSD.
set random_page_cost = 0.9;
Amazon Review Dataset
We’ll use data from the Amazon Review Dataset to demonstrate our optimizations.
Specifically, we’ll use text properties from the 5-core Book Reviews Subset, a dataset of 8.9 million reviews for books sold on Amazon.
An example review shows the shape of our dataset:
{
"reviewerID": "A2SUAM1J3GNN3B",
"asin": "0000013714",
"reviewerName": "J. McDonald",
"helpful": [2, 3],
"reviewText": "I bought this for my husband who plays the piano. ...",
"overall": 5.0,
"summary": "Heavenly Highway Hymns",
"unixReviewTime": 1252800000,
"reviewTime": "09 13, 2009"
}
Each of these reviews includes five text properties: reviewerID, asin, reviewerName, reviewText, summary.
reviewerID and asin are machine-generated identifiers.
reviewerName, reviewText, summary are free-form human-generated text.
For simplicity, we’ll ignore reviewText and make a table with the remaining text properties:
create table reviews (
review_id bigserial primary key,
reviewer_id varchar(50),
reviewer_name varchar(100),
asin varchar(50),
summary varchar(1000)
);
I wouldn’t recommend this schema in a real application.
For example, the reviewer name should be factored out to a reviewer table.
But it’s good enough for a demo.
It takes about 8 minutes to populate the table and the table size ends up at 926MB.
Example Query Strings
We’ll use one of my favorite authors, Michael Lewis, as a test subject.
Specifically, we’ll search for two variations of his name:
- “Michael Lewis” – the correct spelling – to find exact matches
- “Michael Louis” – a plausible misspeling – to find fuzzy matches
To avoid confusion, let’s refer to these as the exact name and the fuzzy name.
Explain (Analyze, Buffers)
We’ll use Postgres’ explain (analyze, buffers) command to evaluate performance.
This command takes a query, executes it, and returns the query plan and execution details.
This is not a fool-proof solution.
A better benchmarking harness would include realistic application request patterns, authentication, authorization, logging, serialization, etc.
However, building such a harness would be pointlessly cumbersome, as it would need to be re-implemented for any other non-trivial application.
The main thing we’re looking at is how the query plan, execution time, and I/O statistics react to optimizations. This is enough to conclude one approach is better than another.
To make this a bit more aesthetically appealing, I cobbled together an embedded version of the excellent PEV2 (Postgres Explain Visualizer 2) project.
Let’s look at an example. I ran this query:
explain (analyze, buffers)
select count(review_id) from reviews;
Which produced this output:
Aggregate (cost=177675.25..177675.26 rows=1 width=8) (actual time=3282.696..3282.697 rows=1 loops=1)
Buffers: shared hit=10 read=24314
I/O Timings: read=121.636
-> Index Only Scan using reviews_pkey on reviews (cost=0.43..155430.15 rows=8898041 width=8) (actual time=1.341..1679.504 rows=8898041 loops=1)
Heap Fetches: 0
Buffers: shared hit=10 read=24314
I/O Timings: read=121.636
Planning Time: 0.138 ms
Execution Time: 3282.768 ms
The PEV2 viewer shows the query plan visualization, raw query plan, query, and some stats.
select count(review_id) from reviews;
Aggregate (cost=177675.25..177675.26 rows=1 width=8) (actual time=3282.696..3282.697 rows=1 loops=1)
Buffers: shared hit=10 read=24314
I/O Timings: read=121.636
-> Index Only Scan using reviews_pkey on reviews (cost=0.43..155430.15 rows=8898041 width=8) (actual time=1.341..1679.504 rows=8898041 loops=1)
Heap Fetches: 0
Buffers: shared hit=10 read=24314
I/O Timings: read=121.636
Planning Time: 0.138 ms
Execution Time: 3282.768 ms
Clicking around a bit in the plan reveals three important results:
- Total planning and execution time: we spent 0.138ms planning and about 3.2s executing.
- Timing and types of execution: we spent 1.6s in an
Aggregate and 1.6s in an Index Only Scan. The Index Only Scan tells us we were able to make use of an index in this query.
- Timing, amount, and types of I/O: if we expand the
Index Only Scan and open the IO and Buffers tab, we see we spent 122ms on I/O, hit 10 blocks, and read 24,314 blocks. A hit means the block was in the shared buffer cache. A read means we went to the filesystem cache or SSD.
Baseline Search Query
With our test environment explained, let’s build a relatively simple baseline query pattern based on the trigram similarity function and its corresponding operators: % and <->.
Trigram Operators
Those already familiar with trigram similarity, %, and <-> can safely skip this section.
First, we need the function similarity(text1, text2).
This function breaks both texts into a set of trigrams, computes the intersection of sets, computes the union of sets, and divides the intersection size by the union size to produce a score between 0 and 1.
In other words, this is the Jaccard Index of the sets of trigrams.
The query below give us some intuition about similarity('abc', 'abb'), 'abc' % 'abb' and 'abc' <-> 'abb':
with input as (select 'abc' as text1, 'abb' as text2)
select
show_trgm(text1) as "text1 trigrams",
show_trgm(text2) as "text2 trigrams",
array(select t1.t1
from unnest(show_trgm(text1)) t1,
unnest(show_trgm(text2)) t2 where t1.t1 = t2.t2) as "intersection",
array(select t1.t1 from unnest(show_trgm(text1)) t1
union
select t2.t2 from unnest(show_trgm(text2)) t2) as "union",
round(similarity(text1, text2)::numeric, 3) as "similarity",
text1 % text2 as "text1 % text2",
text1 <-> text2 as "text1 <-> text2"
from input;
This produces:
| text1 trigrams |
text2 trigrams |
intersection |
union |
similarity |
text1 % text2 |
text1 <-> text2 |
| { a, ab,abc,bc } |
{ a, ab,abb,bb } |
{ a, ab} |
{bb ,abb, a, ab,bc ,abc} |
0.333 |
true |
0.666 |
For “abc” and “abb”, the intersection size is 2 and union size is 6, so 2/6 is a similarity of 1/3.
The operator text1 % text2 returns true if similarity(text1, text2) exceeds a pre-defined threshold setting, pg_trgm.similarity_threshold. The default threshold is 0.3, so select 'abc' % 'abc' returns true.
The operator text1 <-> text2 returns the distance between text1 and text2, which is just 1 - similarity(text1, text2), so select 'abc' <-> 'abb' returns 2/3.
Why do we need these operators if they just alias the similarity function? At the risk of spoiling one of the optimizations, operators can leverage an index, and functions cannot.
Trigram Search Query
Let’s use these operators to search for reviews where summary matches the exact name.
(We should compare the query string against all text columns, but we start with just summary for simplicity.)
The query looks like this:
with input as (select 'Michael Lewis' as q) -- (1)
select review_id,
1.0 - (summary <-> input.q) as score -- (4)
from reviews, input
where input.q % summary -- (2)
order by input.q <-> summary limit 10; -- (3)
Let’s break the query into components, numbered in correspondence to the comments above:
- This is a Common Table Expression (CTE). It gives us a way to reference the query string as a variable,
input.q.
- We use
input.q % summary to filter the table down to a set of candidate rows. For each of these rows, input.q and summary have a trigram similarity greater than or equal to 0.3.
- Once we’ve found candidate rows, we sort them by the trigram distance between
input.q and summary and keep the top 10. We want the rows with highest similarity, which is equivalent to lowest distance. So we sort by the distance operator in ascending order.
- In order to return the score to the user, we just subtract the trigram distance from 1.0.
Let’s look at the results and performance for the exact name:
| review_id |
summary |
score |
| 589771 |
Michael Lewis Fan |
0.7777 |
| 2113780 |
Michael Lewis Fan |
0.7777 |
| 2111282 |
Michael Lewis bland? |
0.6999 |
| 2114048 |
MIchael Lewis is Good |
0.6666 |
| 2100962 |
Not Michael Lewis’ Best |
0.6086 |
| 610753 |
Not Michael Lewis’ Best |
0.6086 |
| 2111364 |
Boomerang, Michael Lewis |
0.5833 |
| 2111212 |
Michael Lewis is amazing |
0.5833 |
| 2111190 |
Michael Lewis on a Roll |
0.5833 |
| 2108446 |
Go Long on Michael Lewis |
0.5833 |
with input as (select 'Michael Lewis' as q)
select review_id,
1.0 - (summary <-> input.q) as score
from reviews, input
where input.q % summary
order by input.q <-> summary limit 10;
Limit (cost=229772.34..229772.37 rows=10 width=20) (actual time=94817.773..94817.777 rows=10 loops=1)
Buffers: shared hit=118549
-> Sort (cost=229772.34..229774.39 rows=819 width=20) (actual time=94817.772..94817.773 rows=10 loops=1)
Sort Key: (('Michael Lewis'::text <-> (reviews.summary)::text))
Sort Method: top-N heapsort Memory: 26kB
Buffers: shared hit=118549
-> Seq Scan on reviews (cost=0.00..229754.64 rows=819 width=20) (actual time=171.828..94816.588 rows=761 loops=1)
Filter: ('Michael Lewis'::text % (summary)::text)
Rows Removed by Filter: 8897280
Buffers: shared hit=118549
Planning Time: 1.669 ms
Execution Time: 94817.814 ms
And again for the fuzzy name:
| review_id |
summary |
score |
| 4341036 |
Lo Michael |
0.6666 |
| 4341045 |
Lo, Michael |
0.6666 |
| 4341030 |
Lo Michael! |
0.6666 |
| 4341034 |
Lo,Michael |
0.6666 |
| 4341027 |
Lo, Michael! |
0.6666 |
| 4341043 |
Lo,Michael |
0.6666 |
| 4341025 |
Lo, Michael! |
0.6666 |
| 4341026 |
Lo. Michael ! |
0.6666 |
| 4341029 |
Lo, Michael! |
0.6666 |
| 4341050 |
Lo michael |
0.6666 |
with input as (select 'Michael Louis' as q)
select review_id,
1.0 - (summary <-> input.q) as score
from reviews, input
where input.q % summary
order by input.q <-> summary limit 10;
Limit (cost=229792.85..229792.87 rows=10 width=20) (actual time=94591.716..94591.720 rows=10 loops=1)
Buffers: shared hit=118549
-> Sort (cost=229792.85..229794.90 rows=821 width=20) (actual time=94591.715..94591.716 rows=10 loops=1)
Sort Key: (('Michael Louis'::text <-> (reviews.summary)::text))
Sort Method: top-N heapsort Memory: 26kB
Buffers: shared hit=118549
-> Seq Scan on reviews (cost=0.00..229775.11 rows=821 width=20) (actual time=176.054..94590.575 rows=729 loops=1)
Filter: ('Michael Louis'::text % (summary)::text)
Rows Removed by Filter: 8897312
Buffers: shared hit=118549
Planning Time: 1.761 ms
Execution Time: 94591.758 ms
Qualitatively speaking, the results are reasonable. There are some exact matches for the exact name, and a few summaries containing “Lo” and “Michael” that match the fuzzy name.
👎 But the performance is terrible: over 94 seconds to find ten results!
If we extrapolate this to all four text columns, we can estimate a runtime of over 360 seconds.
How are we spending this time? The query plans suggest the following:
- About 94s in
Seq Scan on reviews. This is a sequential scan on the reviews table, which means Postgres iterates over all rows and keeps those that satisfy input.q % summary. This returns 761 and 729 matches for the exact and fuzzy names, respectively. The IO & Buffers tabs indicate this also involved reading 926MB of data (i.e., the whole table) from the in-memory cache. It’s better than going to SSD, but it’s still non-negligible.
- About 1ms in
Sort, which sorts the matches by input.q <-> summary.
- Less than 1ms in
Limit, which takes the first ten of the sorted rows.
Baseline Summary
Here’s what we know about our trigram search query so far:
- Qualitatively, it’s not Google, but the results are reasonable.
- The query is unusably slow (over 94s).
- It spends virtually all its time scanning the reviews table.
Optimizations
Let’s get into some optimizations to see if we can improve on the baseline.
Indexing
The first optimization should be unsurprising: we’ll create an index for the text field.
Trigrams support both GIN and GiST index types.
The main difference is that GiST supports filtering and sorting, whereas GIN only supports filtering.
Since our search query involves sorting by trigram distance, we’ll use GiST.
At a high level, the GiST index works by building a lookup table from each trigram to the list or rows containing the trigram.
At query time, Postgres takes the trigrams from the query string and asks the index, “which rows contain these trigrams?”
The trigrams are stored as a signature (i.e., a hash), and sometimes the signatures can collide.
Since Postgres 13, the GiST index type includes a parameter called siglen, which lets us control the precision of the signature. Here’s how the docs describe it:
gist_trgm_ops GiST opclass approximates a set of trigrams as a bitmap signature. Its optional integer parameter siglen determines the signature length in bytes. The default length is 12 bytes. Valid values of signature length are between 1 and 2024 bytes. Longer signatures lead to a more precise search (scanning a smaller fraction of the index and fewer heap pages), at the cost of a larger index.
In short, higher siglen should translate to more precise search (i.e., fewer signature collisions), at the cost of a larger index.
We’ll start with a GiST index with siglen=64, check performance, then repeat with siglen=256.
GiST with siglen=64
create index reviews_summary_trgm_gist_idx on reviews
using gist(summary gist_trgm_ops(siglen=64));
vacuum analyze reviews;
This takes about 10 minutes to build and ends up using about 1000MB of storage.
Does it make a difference for performance?
For the exact name, we find:
with input as (select 'Michael Lewis' as q)
select review_id,
1.0 - (summary <-> input.q) as score
from reviews, input
where input.q % summary
order by input.q <-> summary limit 10;
Limit (cost=0.42..9.81 rows=10 width=20) (actual time=4181.401..4216.478 rows=10 loops=1)
Buffers: shared hit=135684
-> Index Scan using reviews_summary_trgm_gist_idx on reviews (cost=0.42..771.80 rows=821 width=20) (actual time=4181.400..4216.474 rows=10 loops=1)
Index Cond: ((summary)::text % 'Michael Lewis'::text)
Order By: ((summary)::text <-> 'Michael Lewis'::text)
Buffers: shared hit=135684
Planning Time: 1.933 ms
Execution Time: 4216.519 ms
And for the fuzzy name:
with input as (select 'Michael Louis' as q)
select review_id,
1.0 - (summary <-> input.q) as score
from reviews, input
where input.q % summary
order by input.q <-> summary limit 10;
Limit (cost=0.42..9.81 rows=10 width=20) (actual time=4330.713..4330.850 rows=10 loops=1)
Buffers: shared hit=135447
-> Index Scan using reviews_summary_trgm_gist_idx on reviews (cost=0.42..771.80 rows=821 width=20) (actual time=4330.711..4330.845 rows=10 loops=1)
Index Cond: ((summary)::text % 'Michael Louis'::text)
Order By: ((summary)::text <-> 'Michael Louis'::text)
Buffers: shared hit=135447
Planning Time: 1.829 ms
Execution Time: 4330.889 ms
👍 This is a significant improvement: from over 94 seconds to under 4.5 seconds!
If we extrapolate this to all four text columns, we can estimate a runtime of under 20 seconds.
The query plans tell us how we’re making better use of time:
- About 4.3s in an
Index Scan on the new reviews_summary_trgm_gist_idx index. The Misc tab indicates Postgres uses the index for filtering (Index Cond) and sorting (Order By). The IO & Buffers tab indicates we’re accessing 1.03GB of data from the cache. We don’t know precisely, but this data is some combination of the index and the rows.
- Less than 40ms in
Limit. As far as I can tell, this is a trivial pass-through, as the index scan has already returned exactly ten rows.
GiST with siglen=256
Let’s try again with siglen=256:
drop index reviews_summary_trgm_gist_idx;
create index reviews_summary_trgm_gist_idx on reviews
using gist(summary gist_trgm_ops(siglen=256));
vacuum analyze reviews;
This takes about 15 minutes to build and uses 1036MB of storage.
For the exact name, we find:
with input as (select 'Michael Lewis' as q)
select review_id,
1.0 - (summary <-> input.q) as score
from reviews, input
where input.q % summary
order by input.q <-> summary limit 10;
Limit (cost=0.42..9.81 rows=10 width=20) (actual time=503.082..1996.835 rows=10 loops=1)
Buffers: shared hit=62167
-> Index Scan using reviews_summary_trgm_gist_idx on reviews (cost=0.42..771.80 rows=821 width=20) (actual time=503.079..1996.828 rows=10 loops=1)
Index Cond: ((summary)::text % 'Michael Lewis'::text)
Order By: ((summary)::text <-> 'Michael Lewis'::text)
Buffers: shared hit=62167
Planning Time: 5.283 ms
Execution Time: 1997.397 ms
And for the fuzzy name:
with input as (select 'Michael Louis' as q)
select review_id,
1.0 - (summary <-> input.q) as score
from reviews, input
where input.q % summary
order by input.q <-> summary limit 10;
Limit (cost=0.42..9.81 rows=10 width=20) (actual time=707.952..708.081 rows=10 loops=1)
Buffers: shared hit=22639
-> Index Scan using reviews_summary_trgm_gist_idx on reviews (cost=0.42..771.80 rows=821 width=20) (actual time=707.951..708.078 rows=10 loops=1)
Index Cond: ((summary)::text % 'Michael Louis'::text)
Order By: ((summary)::text <-> 'Michael Louis'::text)
Buffers: shared hit=22639
Planning Time: 1.654 ms
Execution Time: 708.577 ms
👍 Another improvement: from 4.5 seconds to under 2 seconds!
If we extrapolate this to all four text columns, we can estimate a runtime of about 8 seconds.
Why does Siglen Matter?
Inspection of these results leads to two questions:
- Why is siglen=256 over 2x faster than siglen=64?
- For siglen=256, why is the exact name over 2x faster than the fuzzy name?
We can begin to answer these by looking at the IO & Buffers tabs, which tell us how much data was accessed. The numbers work out like this:
| Siglen |
Query String |
Data Accessed |
Access Type |
| 64 |
exact name |
1.04GB |
hit (from in-memory cache) |
| 64 |
fuzzy name |
1.03GB |
hit (from in-memory cache) |
| 256 |
exact name |
486MB |
hit (from in-memory cache) |
| 256 |
fuzzy name |
177MB |
hit (from in-memory cache) |
Even though this data is in memory, decreasing the amount accessed makes a difference.
I’m still working on an intuitive understanding of why these two specific values of siglen work out to these specific differences, but that’s likely a topic for another post.
Indexing Summary
Here’s what we know about indexing:
- Adding a GiST index yields a significant speedup: 94s → 4.5s.
- Increasing the siglen parameter from 64 to 256 yields another speedup: 4.5s → 2s.
- The siglen parameter affects the number of buffers read to execute the index scan: greater siglen → fewer buffers → faster query.
Separate Exact and Trigram Search Queries
Recall that we’re interested in both exact and fuzzy matches.
So far, we’ve used a single trigram search query to satisfy both match types.
Trigrams are useful for fuzzy matches, but are they really necessary for exact matches?
Let’s take a step back, compose an exact-only search query, and see what we can do with it.
The ilike operator
The boolean operator text1 ilike '%' || text2 || '%' will return true if text1 contains text2, ignoring capitalization.
Here are some examples:
select
'abc' ilike '%' || 'ab' || '%' as "abc contains ab",
'abc' ilike '%' || 'AB' || '%' as "abc contains AB",
'abc' ilike '%' || 'abc' || '%' as "abc contains abc",
'abc' ilike '%' || 'abb' || '%' as "abc contains abb"
This produces:
| abc contains ab |
abc contains AB |
abc contains abc |
abc contains abb |
| true |
true |
true |
false |
Exact-Only Search Query
We can use the ilike operator compose an exact-only search query:
with input as (select 'Michael Lewis' as q)
select review_id,
1.0 as score -- (2)
from reviews, input
where summary ilike '%' || input.q || '%' -- (1)
limit 10; -- (3)
- We use the
ilike operator to filter for rows where summary contains the query string.
- Since each
summary contains the query string, we simply assign a score of 1.0.
- We just want ten of them. They all have the same score, so no need to sort.
How does it perform on our query strings?
For the exact name, we find:
with input as (select 'Michael Lewis' as q)
select review_id,
1.0 as score
from reviews, input
where summary ilike '%' || input.q || '%'
limit 10;
Limit (cost=0.42..9.71 rows=10 width=40) (actual time=2.955..6.431 rows=10 loops=1)
Buffers: shared hit=865
-> Index Scan using reviews_summary_trgm_gist_idx on reviews (cost=0.42..763.59 rows=821 width=40) (actual time=2.952..6.425 rows=10 loops=1)
Index Cond: ((summary)::text ~~* '%Michael Lewis%'::text)
Buffers: shared hit=865
Planning Time: 0.413 ms
Execution Time: 6.456 ms
And for the fuzzy name:
with input as (select 'Michael Louis' as q)
select review_id,
1.0 as score
from reviews, input
where summary ilike '%' || input.q || '%'
limit 10;
Limit (cost=0.42..9.71 rows=10 width=40) (actual time=10.582..10.583 rows=0 loops=1)
Buffers: shared hit=1429
-> Index Scan using reviews_summary_trgm_gist_idx on reviews (cost=0.42..763.59 rows=821 width=40) (actual time=10.581..10.581 rows=0 loops=1)
Index Cond: ((summary)::text ~~* '%Michael Louis%'::text)
Rows Removed by Index Recheck: 1
Buffers: shared hit=1429
Planning Time: 0.340 ms
Execution Time: 10.007 ms
👍 A significant improvement: from 2s to 10ms!
If we extrapolate to all four text columns, we’re down to potentially 40ms.
This tells us that finding exact matches with an exact-only query is significantly faster than finding them with a trigram search query.
The query plan is roughly the same as our trigram search query, basically just an Index Scan on reviews, but the amount of data accessed is significantly lower: under 12MB.
Crucially, this presents an opportunity for optimization: given a query string and a desired number of results, we first attempt to very quickly search for exact matches.
If we find the desired number of results, we can skip the fuzzy search entirely.
If we don’t find all the results, we run the fuzzy query.
If we want to get fancy, we can even run the two searches in parallel and cancel the fuzzy search if our exact search is sufficient.
Separate Queries Summary
Here’s what we know about separating exact and trigram search queries:
- An exact-only query accesses significantly less data than a trigram query: 177MB → 11MB
- An exact-only query is significantly faster than a trigram query: 2s → 10ms
- If the exact-only query finds enough results, we can skip the fuzzy query.
- In the best case, we turn a 2s search into a 10ms search.
- In the worst case, we turn a 2s search into a 2.01s search.
Single Query for All Text Columns
So far our search queries have only checked for matches in the summary column, and we’ve been extrapolating the timing.
Now is the time to stop extrapolating and compose a query that actually checks all four text columns.
Let’s look at three ways we can make this happen.
Four Single-Column Queries
The simplest method to check each of the columns is to simply search for every column separately.
Then we would deduplicate and re-rank the results in application code.
To do this, we start by building indexes on the three remaining columns:
create index reviews_reviewer_id_trgm_gist_idx on reviews
using gist(reviewer_id gist_trgm_ops(siglen=256));
create index reviews_reviewer_name_trgm_gist_idx on reviews
using gist(reviewer_name gist_trgm_ops(siglen=256));
create index reviews_asin_trgm_gist_idx on reviews
using gist(asin gist_trgm_ops(siglen=256));
vacuum analyze reviews;
Each of these takes about fifteen minutes to build and uses about 690MB of storage.
The trigram search query is just a union of the original trigram search query on each column:
with input as (select 'Michael Lewis' as q)
(select review_id, 1.0 - (reviewer_id <-> input.q) as score
from reviews, input
where input.q % reviewer_id
order by input.q <-> reviewer_id limit 10)
union all
(select review_id, 1.0 - (reviewer_name <-> input.q) as score
from reviews, input
where input.q % reviewer_name
order by input.q <-> reviewer_name limit 10)
union all
(select review_id, 1.0 - (summary <-> input.q) as score
from reviews, input
where input.q % summary
order by input.q <-> summary limit 10)
union all
(select review_id, 1.0 - (asin <-> input.q) as score
from reviews, input
where input.q % asin
order by input.q <-> asin limit 10);
The exact-only query follows the same pattern:
explain (analyze, buffers)
with input as (select 'Michael Lewis' as q)
(select review_id, 1.0 as score
from reviews, input
where reviewer_id ilike '%' || input.q || '%'
limit 10)
union all
(select review_id, 1.0 as score
from reviews, input
where reviewer_name ilike '%' || input.q || '%'
limit 10)
union all
(select review_id, 1.0 as score
from reviews, input
where summary ilike '%' || input.q || '%'
limit 10)
union all
(select review_id, 1.0 as score
from reviews, input
where asin ilike '%' || input.q || '%'
limit 10);
Before analyzing the query execution, let’s review our thinking on how long this should take.
Our latest queries looked at the summary column and took about 10ms for exact-only search and 2s for trigram search.
We have four text columns, so it’s not crazy to estimate somewhere between 40ms and 8s for four one-column queries.
The actual performance works out like this:
| Query |
Query String |
Execution Time |
Buffer Hits |
| Trigram |
exact name |
10.7s |
336986 |
| Trigram |
fuzzy name |
11.2s |
336998 |
| Exact-Only |
exact name |
144ms |
12684 |
| Exact-Only |
fuzzy name |
94ms |
9263 |
👎 The performance is pretty bad: about 11s to find ten matches.
All four plans are roughly identical, so let’s look at the trigram query for the exact name:
with input as (select 'Michael Lewis' as q)
(select review_id, 1.0 - (reviewer_id <-> input.q) as score
from reviews, input
where input.q % reviewer_id
order by input.q <-> reviewer_id limit 10)
union all
(select review_id, 1.0 - (reviewer_name <-> input.q) as score
from reviews, input
where input.q % reviewer_name
order by input.q <-> reviewer_name limit 10)
union all
(select review_id, 1.0 - (summary <-> input.q) as score
from reviews, input
where input.q % summary
order by input.q <-> summary limit 10)
union all
(select review_id, 1.0 - (asin <-> input.q) as score
from reviews, input
where input.q % asin
order by input.q <-> asin limit 10);
Append (cost=64064.97..256647.56 rows=40 width=16) (actual time=6764.697..10795.095 rows=20 loops=1)
Buffers: shared hit=336986
CTE input
-> Result (cost=0.00..0.01 rows=1 width=32) (actual time=0.001..0.002 rows=1 loops=1)
" -> Subquery Scan on ""*SELECT* 1_1"" (cost=64064.96..64065.09 rows=10 width=16) (actual time=2506.643..2506.645 rows=0 loops=1)"
Buffers: shared hit=69700
-> Limit (cost=64064.96..64064.99 rows=10 width=20) (actual time=2506.642..2506.643 rows=0 loops=1)
Buffers: shared hit=69700
-> Sort (cost=64064.96..64287.41 rows=88980 width=20) (actual time=2506.641..2506.642 rows=0 loops=1)
Sort Key: ((input.q <-> (reviews.reviewer_id)::text))
Sort Method: quicksort Memory: 25kB
Buffers: shared hit=69700
-> Nested Loop (cost=0.42..62142.14 rows=88980 width=20) (actual time=2506.636..2506.636 rows=0 loops=1)
Buffers: shared hit=69700
-> CTE Scan on input (cost=0.00..0.02 rows=1 width=32) (actual time=0.003..0.005 rows=1 loops=1)
-> Index Scan using reviews_reviewer_id_trgm_gist_idx on reviews (cost=0.42..60584.97 rows=88980 width=22) (actual time=2506.628..2506.628 rows=0 loops=1)
Index Cond: ((reviewer_id)::text % input.q)
Buffers: shared hit=69700
" -> Subquery Scan on ""*SELECT* 2"" (cost=64056.86..64056.99 rows=10 width=16) (actual time=4258.051..4258.058 rows=10 loops=1)"
Buffers: shared hit=133720
-> Limit (cost=64056.86..64056.89 rows=10 width=20) (actual time=4258.048..4258.052 rows=10 loops=1)
Buffers: shared hit=133720
-> Sort (cost=64056.86..64279.31 rows=88980 width=20) (actual time=4258.047..4258.049 rows=10 loops=1)
Sort Key: ((input_1.q <-> (reviews_1.reviewer_name)::text))
Sort Method: top-N heapsort Memory: 26kB
Buffers: shared hit=133720
-> Nested Loop (cost=0.42..62134.04 rows=88980 width=20) (actual time=0.750..4239.400 rows=50214 loops=1)
Buffers: shared hit=133720
-> CTE Scan on input input_1 (cost=0.00..0.02 rows=1 width=32) (actual time=0.001..0.002 rows=1 loops=1)
-> Index Scan using reviews_reviewer_name_trgm_gist_idx on reviews reviews_1 (cost=0.42..60576.87 rows=88980 width=24) (actual time=0.722..3483.767 rows=50214 loops=1)
Index Cond: ((reviewer_name)::text % input_1.q)
Buffers: shared hit=133720
" -> Subquery Scan on ""*SELECT* 3"" (cost=64460.96..64461.09 rows=10 width=16) (actual time=4022.956..4022.963 rows=10 loops=1)"
Buffers: shared hit=132744
-> Limit (cost=64460.96..64460.99 rows=10 width=20) (actual time=4022.954..4022.957 rows=10 loops=1)
Buffers: shared hit=132744
-> Sort (cost=64460.96..64683.41 rows=88980 width=20) (actual time=4022.953..4022.954 rows=10 loops=1)
Sort Key: ((input_2.q <-> (reviews_2.summary)::text))
Sort Method: top-N heapsort Memory: 26kB
Buffers: shared hit=132744
-> Nested Loop (cost=0.42..62538.14 rows=88980 width=20) (actual time=8.015..4022.513 rows=761 loops=1)
Buffers: shared hit=132744
-> CTE Scan on input input_2 (cost=0.00..0.02 rows=1 width=32) (actual time=0.000..0.002 rows=1 loops=1)
-> Index Scan using reviews_summary_trgm_gist_idx on reviews reviews_2 (cost=0.42..60980.97 rows=88980 width=34) (actual time=7.986..4009.293 rows=761 loops=1)
Index Cond: ((summary)::text % input_2.q)
Buffers: shared hit=132744
" -> Subquery Scan on ""*SELECT* 4"" (cost=64064.06..64064.19 rows=10 width=16) (actual time=7.418..7.419 rows=0 loops=1)"
Buffers: shared hit=822
-> Limit (cost=64064.06..64064.09 rows=10 width=20) (actual time=7.417..7.418 rows=0 loops=1)
Buffers: shared hit=822
-> Sort (cost=64064.06..64286.51 rows=88980 width=20) (actual time=7.416..7.417 rows=0 loops=1)
Sort Key: ((input_3.q <-> (reviews_3.asin)::text))
Sort Method: quicksort Memory: 25kB
Buffers: shared hit=822
-> Nested Loop (cost=0.42..62141.24 rows=88980 width=20) (actual time=7.410..7.411 rows=0 loops=1)
Buffers: shared hit=822
-> CTE Scan on input input_3 (cost=0.00..0.02 rows=1 width=32) (actual time=0.000..0.001 rows=1 loops=1)
-> Index Scan using reviews_asin_trgm_gist_idx on reviews reviews_3 (cost=0.42..60584.07 rows=88980 width=19) (actual time=7.406..7.406 rows=0 loops=1)
Index Cond: ((asin)::text % input_3.q)
Buffers: shared hit=822
Planning Time: 0.433 ms
Execution Time: 10795.196 ms
Here’s how we spend this time:
- Just over 10s in four
Index Scan blocks (one per column). These scans return 50,214 rows for reviewer_name, 761 rows for summary and 0 rows for asin and reviewer_id. In total, they access about 2.59GB of data from the shared buffer cache.
- 769ms in
Nested Loop blocks. These loops combine the input with the Index Scan results. It’s rather surprising that we spend any significant time here, but we could easily optimize this out by getting rid of the input CTE.
If we want to search all four text columns, we’ll need to think a bit harder!
One Four-Column Query with Disjunctions
As a second pass, what if we flatten the four unioned queries into a single disjunctive query?
select review_id,
(1 - least(
input.q <-> reviewer_id,
input.q <-> reviewer_name,
input.q <-> summary,
input.q <-> asin)) as score -- (3)
from reviews, input
where input.q % reviewer_id
or input.q % reviewer_name
or input.q % summary
or input.q % asin -- (1)
order by least(
input.q <-> reviewer_id,
input.q <-> reviewer_name,
input.q <-> summary,
input.q <-> asin) limit 10; -- (2)
Explaining the numbered components:
- We keep the row as a candidate if it’s a trigram match for any of the four columns.
- We sort the candidates by the lowest trigram distance to any of the four queries.
- We score the candidates by one minus the lowest trigram distance to any of the four queries. This is equivalent to the greatest trigram similarity.
The performance works out like this:
| Query |
Query String |
Execution Time |
Buffer Hits |
| Trigram |
exact name |
13.8s |
323953 |
| Trigram |
fuzzy name |
13.9s |
324728 |
| Exact-Only |
exact name |
162ms |
14705 |
| Exact-Only |
fuzzy name |
153ms |
12987 |
👎 The performance is even worse: about 14s to find ten matches.
explain (analyze, buffers)
with input as (select 'Michael Lewis' as q)
select review_id,
(1 - least(
input.q <-> reviewer_id,
input.q <-> reviewer_name,
input.q <-> summary,
input.q <-> asin)) as score -- (3)
from reviews, input
where input.q % reviewer_id
or input.q % reviewer_name
or input.q % summary
or input.q % asin -- (1)
order by least(
input.q <-> reviewer_id,
input.q <-> reviewer_name,
input.q <-> summary,
input.q <-> asin) limit 10; -- (2)
Limit (cost=5389.77..5389.79 rows=10 width=20) (actual time=13856.366..13856.370 rows=10 loops=1)
Buffers: shared hit=323953
-> Sort (cost=5389.77..5403.40 rows=5452 width=20) (actual time=13856.364..13856.367 rows=10 loops=1)
" Sort Key: (LEAST(('Michael Lewis'::text <-> (reviews.reviewer_id)::text), ('Michael Lewis'::text <-> (reviews.reviewer_name)::text), ('Michael Lewis'::text <-> (reviews.summary)::text), ('Michael Lewis'::text <-> (reviews.asin)::text)))"
Sort Method: top-N heapsort Memory: 26kB
Buffers: shared hit=323953
-> Bitmap Heap Scan on reviews (cost=102.01..5271.95 rows=5452 width=20) (actual time=10013.108..13837.707 rows=50929 loops=1)
Recheck Cond: (('Michael Lewis'::text % (reviewer_id)::text) OR ('Michael Lewis'::text % (reviewer_name)::text) OR ('Michael Lewis'::text % (summary)::text) OR ('Michael Lewis'::text % (asin)::text))
Filter: (('Michael Lewis'::text % (reviewer_id)::text) OR ('Michael Lewis'::text % (reviewer_name)::text) OR ('Michael Lewis'::text % (summary)::text) OR ('Michael Lewis'::text % (asin)::text))
Heap Blocks: exact=34021
Buffers: shared hit=323953
-> BitmapOr (cost=102.01..102.01 rows=5453 width=0) (actual time=9995.890..9995.892 rows=0 loops=1)
Buffers: shared hit=289932
-> Bitmap Index Scan on reviews_reviewer_id_trgm_gist_idx (cost=0.00..15.07 rows=874 width=0) (actual time=2488.516..2488.517 rows=0 loops=1)
Index Cond: ((reviewer_id)::text % 'Michael Lewis'::text)
Buffers: shared hit=69700
-> Bitmap Index Scan on reviews_reviewer_name_trgm_gist_idx (cost=0.00..48.25 rows=2898 width=0) (actual time=3429.824..3429.824 rows=50214 loops=1)
Index Cond: ((reviewer_name)::text % 'Michael Lewis'::text)
Buffers: shared hit=87344
-> Bitmap Index Scan on reviews_summary_trgm_gist_idx (cost=0.00..18.28 rows=821 width=0) (actual time=4070.030..4070.030 rows=761 loops=1)
Index Cond: ((summary)::text % 'Michael Lewis'::text)
Buffers: shared hit=132066
-> Bitmap Index Scan on reviews_asin_trgm_gist_idx (cost=0.00..14.96 rows=859 width=0) (actual time=7.515..7.515 rows=0 loops=1)
Index Cond: ((asin)::text % 'Michael Lewis'::text)
Buffers: shared hit=822
Planning Time: 5.831 ms
Execution Time: 13856.489 ms
Here’s how we spend this time:
- About 10s in four
Bitmap Index Scan blocks, one per text column. Just like the previous iteration, these scans return 50,214 and 761 rows for reviewer_name and summary, respectively. In total, they access about 2.24GB of data from the shared buffer cache.
- About 3s in a
Bitmap Heap Scan. This step deduplicates the data returned from the Bitmap Index Scan blocks. Unfortunately, it only removes 46 of the 50975 rows returned from the scans, and it accesses another 266MB of data from the shared buffer cache.
- About 20ms in a
Sort block that sorts the 50,929 rows returned from the previous blocks.
Alas, the query is a bit more compact, but it doesn’t make very good use of time.
One Four-Column Query with an Expression Index
Let’s give this one more try.
For this final pass, we’ll need to introduce two new concepts: expression indexes and trigram word_similarity.
Expression Indexes
An Expression Index lets us apply some function to a set of columns (all on the same table) and index the resulting values.
The canonical example is a query for a full name against a table with first_name and last_name columns:
SELECT * FROM people WHERE (first_name || ' ' || last_name) = 'John Smith';
We don’t want to store a full_name column, as that would duplicate data and probably drift.
Instead, we can create an index on the same name concatenation:
CREATE INDEX people_names ON people ((first_name || ' ' || last_name));
Then, any query with the same expression can leverage the index – pretty cool if you ask me.
word_similarity
The trigram word_similarity(text1, text2) function is a variation on the similarity(text1, text2) function.
As a reminder, similarity(text1, text2) computes the intersection-over-union of the two trigram sets.
In contrast, word_similarity(text1, text2) computes the greatest similarity between the set of trigrams in the first string and any continuous extent of an ordered set of trigrams in the second string.
That is quite a mouthful.
For our purposes, the point is this: similarity is sensitive to the length of the two strings, whereas word_similarity is not!
Let’s look at an example that demonstrates the sensitivity to string length:
select text1, text2, similarity(text1, text2), word_similarity(text1, text2)
from
(values ('louis', 'lewis'),
('louis', 'a lewis c'),
('louis', 'aa lewis cc'),
('louis', 'aaa lewis ccc')) v(text1, text2);
Note how the similarity decreases as the length of text2 increases, whereas word_similarity remains constant.
| text1 |
text2 |
similarity |
word_similarity |
| louis |
lewis |
0.2 |
0.2 |
| louis |
a lewis c |
0.14285715 |
0.2 |
| louis |
aa lewis cc |
0.125 |
0.2 |
| louis |
aaa lewis ccc |
0.11111111 |
0.2 |
Why does this property matter?
I don’t want to give too much away, but we just described an indexing technique that leverages concatenated text columns.
Concatenated text columns are, by definition, longer than individual text columns.
Some final details, for sake of completeness:
- The order of arguments matters.
word_similarity(text1, text2) will only equal word_similarity(text2, text1) if text1 = text2.
- The
text1 <<-> text2 operator is used to compute word_similarity distance, i.e., 1 - word_similarity(text1, text2). This is analogous to text1 <-> text2 and 1 - similarity(text1, text2).
- The
text1 <<% text2 operator is used to filter for word_similarity(text1, text2) exceeding a fixed threshold. The default threshold is 0.6.
A Blazing Fast Search Query
Let’s put our knowledge of expression indexes and word_similarity to use.
We’ll start by building an index on the concatenation expression of all four text columns.
We have to coalesce the columns to empty strings, as they are all nullable.
create index reviews_searchable_text_trgm_gist_idx on reviews
using gist((
coalesce(asin, '') || ' ' ||
coalesce(reviewer_id, '') || ' ' ||
coalesce(reviewer_name, '') || ' ' ||
coalesce(summary, '')) gist_trgm_ops(siglen=256));
This takes about 16 minutes to build and ends up using about 2.2GB of storage.
Now we need a search query that can leverage this index.
Behold, our new trigram search query:
with input as (select 'Michael Louis' as q)
select review_id,
1 - (input.q <<-> (coalesce(asin, '') || ' ' ||
coalesce(reviewer_id, '') || ' ' ||
coalesce(reviewer_name, '') || ' ' ||
coalesce(summary, ''))) as score -- (3)
from reviews, input
where input.q <% (coalesce(asin, '') || ' ' ||
coalesce(reviewer_id, '') || ' ' ||
coalesce(reviewer_name, '') || ' ' ||
coalesce(summary, '')) -- (1)
order by input.q <<-> (coalesce(asin, '') || ' ' ||
coalesce(reviewer_id, '') || ' ' ||
coalesce(reviewer_name, '') || ' ' ||
coalesce(summary, '')) limit 10; -- (2)
The numbered components should help cut through the concatenations:
- We use
input.q <% concatenated_columns to filter the table down to a set of candidate rows. For each of these rows, input.q and the concatenated columns have a trigram word similarity greater than or equal to 0.6.
- Once we have candidate rows, we compute and sort by the trigram word distance between
input.q and the concatenated columns.
- In order to return the score, we just subtract the trigram word distance from 1.0.
The corresponding exact-only search query looks similar:
explain (analyze, buffers)
with input as (select 'Michael Lewis' as q)
select review_id,
1.0 as score
from reviews, input
where (coalesce(asin, '') || ' ' ||
coalesce(reviewer_id, '') || ' ' ||
coalesce(reviewer_name, '') || ' ' ||
coalesce(summary, '')) ilike '%' || input.q || '%'
limit 10;
The results for the trigram search query on the exact name look like this:
| review_id |
asin |
reviewer_id |
reviewer_name |
summary |
score |
| 2108562 |
0393072231 |
A22GLZ0P4MGO0W |
Thom Mitchell |
Another Michael Lewis Must Read |
1 |
| 2111265 |
0393081818 |
A1VJF95Y8HMXW9 |
Louis Kokernak |
Another fun and informative read from Michael Lewis |
1 |
| 2114047 |
0393244660 |
A13U0KMO103QJP |
Larry L. Roberts |
Another great book by Michael Lewis. A must read for the small investor. |
1 |
| 2108273 |
0393072231 |
A1P1WJTZGC955H |
ITS |
Another Michael Lewis Masterpiece |
1 |
| 2097231 |
0393057658 |
A3MYOI5BL91KKA |
Joseph M. Powers |
Standard, high quality, Michael Lewis offering |
1 |
| 2097049 |
0393057658 |
A2QHM5HBSIXRL4 |
Andy Orrock |
Another good work from Michael Lewis |
1 |
| 2113780 |
0393244660 |
APM2KUPZYHB94 |
Alice |
Michael Lewis Fan |
1 |
| 2108394 |
0393072231 |
A2JOZET739XZT7 |
Mark Haslett |
Big Fan of Michael Lewis |
1 |
| 2108244 |
0393072231 |
A27NDIDE8W9YQC |
Gderf |
The Big Short by Michael Lewis |
1 |
| 2111212 |
0393081818 |
A2X1XC7SQQGXFH |
Ian C Freund |
Michael Lewis is amazing |
1 |
And the trigram search query on the fuzzy name:
| review_id |
asin |
reviewer_id |
reviewer_name |
summary |
score |
| 1368320 |
0316013684 |
A106393MZH9T4M |
Michael Louis Minns |
Fun and enlightening |
1 |
| 1683931 |
0345536592 |
A106393MZH9T4M |
Michael Louis Minns |
Odd Thomas Collection |
1 |
| 3803521 |
077831233X |
A106393MZH9T4M |
Michael Louis Minns |
Real law by a real lawyer |
1 |
| 2990026 |
0553808036 |
A106393MZH9T4M |
Michael Louis Minns |
Koontz Remains the Master |
1 |
| 5497049 |
1455546143 |
A106393MZH9T4M |
Michael Louis Minns |
Could not put this down… |
1 |
| 1856766 |
0375411089 |
A106393MZH9T4M |
Michael Louis Minns |
skinny dip |
1 |
| 2000799 |
0385343078 |
A106393MZH9T4M |
Michael Louis Minns |
Great Historical Fiction |
1 |
| 3836540 |
0778327760 |
A106393MZH9T4M |
Michael Louis Minns |
Teller Rocks |
1 |
| 5536658 |
1460201051 |
A106393MZH9T4M |
Michael Louis Minns |
The Cat Didn’t really do it |
1 |
| 3478374 |
074326875X |
A106393MZH9T4M |
Michael Louis Minns |
Pretty good read |
1 |
It turns out there was an avid reviewer named Michael Louis. Go figure!
Performance works out like this:
| Query |
Query String |
Execution Time |
Buffer Hits |
| Trigram |
exact name |
39ms |
1685 |
| Trigram |
fuzzy name |
113ms |
5094 |
| Exact-Only |
exact name |
37ms |
4345 |
| Exact-Only |
fuzzy name |
87ms |
10633 |
👍 A significant improvement: from over 10s to just over 100ms!
Let’s look at the plan for trigram search with the exact name to understand why this is faster:
with input as (select 'Michael Lewis' as q)
select review_id,
1 - (input.q <<-> (coalesce(asin, '') || ' ' ||
coalesce(reviewer_id, '') || ' ' ||
coalesce(reviewer_name, '') || ' ' ||
coalesce(summary, ''))) as score -- (3)
from reviews, input
where input.q <% (coalesce(asin, '') || ' ' ||
coalesce(reviewer_id, '') || ' ' ||
coalesce(reviewer_name, '') || ' ' ||
coalesce(summary, '')) -- (1)
order by input.q <<-> (coalesce(asin, '') || ' ' ||
coalesce(reviewer_id, '') || ' ' ||
coalesce(reviewer_name, '') || ' ' ||
coalesce(summary, '')) limit 10; -- (2)
Limit (cost=0.42..7.82 rows=10 width=20) (actual time=8.202..38.716 rows=10 loops=1)
Buffers: shared hit=1685
-> Index Scan using reviews_searchable_text_trgm_gist_idx on reviews (cost=0.42..65909.97 rows=88980 width=20) (actual time=8.200..38.709 rows=10 loops=1)
" Index Cond: ((((((((COALESCE(asin, ''::character varying))::text || ' '::text) || (COALESCE(reviewer_id, ''::character varying))::text) || ' '::text) || (COALESCE(reviewer_name, ''::character varying))::text) || ' '::text) || (COALESCE(summary, ''::character varying))::text) %> 'Michael Lewis'::text)"
Rows Removed by Index Recheck: 3
" Order By: ((((((((COALESCE(asin, ''::character varying))::text || ' '::text) || (COALESCE(reviewer_id, ''::character varying))::text) || ' '::text) || (COALESCE(reviewer_name, ''::character varying))::text) || ' '::text) || (COALESCE(summary, ''::character varying))::text) <->> 'Michael Lewis'::text)"
Buffers: shared hit=1685
Planning Time: 0.176 ms
Execution Time: 38.772 ms
One last time, here’s how we spend our time:
- About 40ms in an
Index Scan block. This uses the new reviews_searchable_text_trgm_gist_idx index for filtering and sorting and returns exactly 10 rows. It accesses just over 13MB of data from the shared buffer cache.
Single Query Summary
Here’s what we know about combining four columns in a single query:
- Unioning four queries was more than a 4x slowdown: 2s for one column → 10s for four.
- Introducing a clever disjunction made it even slower: 10s → 14s.
- Leveraging an expression index and a new trigram operator is our winner: 10s → 113ms.
Conclusion
Through some effort and iteration, we’ve arrived at a very performant query.
We started at 90 seconds to search one text column and ended at 113ms for four columns.
Our implementation consisted primarily of Postgres trigram and string matching operators, and our optimizations used three main techniques:
- Indexing the text columns
- Separating exact search queries from trigram search queries
- Cleverly combining all four text columns into a single index and single query
Throughout the iterations, we leveraged explain (analyze, buffers) with the PEV2 visualizer to understand how we were spending our time on execution and I/O.
As always, I hope this post will save someone a bit of time learning, debugging, and optimizing!
Appendix
Discussion
Potential Improvements
Some folks have responded with interesting suggestions for potential improvements.
I’ll cover them below, and might eventually try some of them and update the post.
Generated Columns
In episode 204 of the Scaling Postgres Podcast, around 8:30, the host made a nice suggestion that we might be able to use the Generated Columns feature to minimize the string concatenation boilerplate from the final query.
Some commentors on Hackernews also mentioned that the string concatenation is tedious.
I agree it’s hard to read.
We also have to be careful to ensure that our concatenation matches the exact expression used in the Expression Index, otherwise we won’t hit the index, which could be a subtle and painful performance regression.
I’ve never used the Generated Columns feature, but I think the solution might look something like this: define a fifth generated text column, specify that the column is generated as the concatenation of the four other columns, build a standard index on that column, and reference that column in search queries.
I think this could work.
My only hesitation would be that the generated column is materialized, so it takes up additional space.
The docs say specifically, “PostgreSQL currently implements only stored generated columns.”
Depending on the size of the table, it might not make any difference and optimizing for readability/simplicity would be great.
But that tradeoff seems worth remembering.
Materialized Views
Some commentors on Hackernews mentioned that things get tricky if we have text columns on multiple tables and suggested it might be easier to move all of the text data into a materialized view.
I agree this could work, with some caveats.
The data model would have to allow for mapping each searchable “entity” to a single row in the materialized view.
This can get tricky with 1:N relationships.
For example, imagine a database for a blog: an article can have many comments, with articles and comments in their own separate tables.
We want to search for articles, such that our query matches against both the article text and the corresponding comment text.
Our query could match multiple comments for the same article, but we only want to return the article once.
We would have to find a way to represent an article and all its comments as a single row in a materialized view, and it’s not immediately obvious how we would do that.
We have to account for eventual consistency.
For example, imagine the same database for a blog.
A user can delete an article or comment, but it remains in the materialized view until the next refresh.
Now we need some filtering logic to prevent returning stale results from the materialized view.
This could introduce complexity that cancels out any wins from using the materialized view in the first place.
I find that eventual consistency is a reality we should all accept in distributed systems, but we should also try to prevent introducing it within a single relational database.
Finally, we would also need a reliable mechanism to refresh the materialized view.
This is actually the biggest pitfall in my opinion: I’ve yet to find a satisfying mechanism for refreshing without introducing unfortunate performance dynamics, like decreasing query throughput every five minutes because the refresh is hogging resources.
This is also why I’m particularly excited about a new Postgres feature currently under development, Incremental View Maintenance (IVM).
With IVM, the promise is that we can define a materialized view that is atomically updated on any write to the source table.
I encourage folks to look around the docs and discussions surrounding the feature – it’s quite interesting.
]]>