Sane Scala Dependencies in a Poly-Repo Codebase
Introduction
In this post I’ll offer some good practices for managing Scala dependencies in a poly-repo codebase. In other words, I have some tips for avoiding dependency hell when working across multiple Scala/SBT projects.
There are many definitions of dependency hell. For me it’s tracing through a half-dozen repos to fix a cryptic NoSuchMethodError or spending a day bumping versions and releasing artifacts to propagate a trivial bug-fix across several repos.
I’ll start by defining some anti-patterns which lead to dependency hell. Then I’ll provide several solutions which require only existing tools and discipline. I’ll cover my experience with Scala Steward, a tool that offers tremendous value if used correctly and moderate chaos if not. Finally, I’ll sketch out some features I’d like to see in SBT or perhaps an open-source SBT plugin.
The problems and solutions I’ll cover are based on almost three years in a poly-repo Scala codebase. I grew into the role of “SBT guy” and spent time simplifying dependency graphs, fixing dependency conflicts, re-structuring repos, reviewing PRs for backwards-compatibility, and improving various build tools to support all of the above.
It’s unlikely any solutions I present are particularly novel. I learned them through a combination of trial and error and exploring major open-source projects. They’re all fairly obvious, especially after you’ve burned yourself a few times. Finally, the exact terms and examples are specific to Scala and SBT, but the principles should apply to other languages and build tools.
A Poly-Repo Codebase
To be clear, here’s what I mean by poly-repo codebase:
- Around ten to twenty repos – enough to overwhelm a new-hire, but an experienced developer with some tribal knowledge can keep a mental model.
- Each repo is a single SBT project, typically with SBT sub-projects. Repo and SBT project are interchangeable concepts.
- Each repo produces one or more artifacts. E.g., a service publishes its backend as a Docker container and client as a JAR.
- Each repo is of non-trivial scope and complexity. Let’s say a full round of CI/CD for one repo takes about 30 minutes.
- There are dependency chains spanning multiple repos. E.g.,
megacorp-backenddepends onmegacorp-ssodepends onmegacorp-utils, and all three artifacts are published from separate repos.
The Roads to Dependency Hell
Version Conflicts
When we add a dependency, we also add transitive dependencies (the dependency’s dependencies). Each of these has a specific version, and it’s inevitable that any interesting project will end up with conflicting versions among its transitive dependencies.
A concrete example: say we use akka-http in a service and want to add akka-grpc. We already use circe and akka-http-circe for marshaling JSON in akka-http. akka-grpc uses scalapb for generating Protobufs, but we still need some Protobuf-to-JSON conversion for backwards compatibility. So we grab scalapb-circe, which uses circe to convert protobufs to and from JSON.
At this point our dependencies look like this:

An arrow from A to B indicates that A depends on B, and each of these arrows is a new opportunity to introduce a version conflict. As of January 2021 there exists no conflict-free combination of these dependencies. For example, akka-grpc 1.0.2 depends on scalapb-runtime 0.10.8, but there’s no version of scalapb-circe which depends on scalapb at exactly 0.10.8.
So they actually look more like this:

Note that scalapb-circe and akka-http-circe might also depend on different versions of circe, and akka-grpc and akka-http-circe might depend on different versions of akka-http. So if we’re really unlucky we end up with this:

This is an exaggeration for this particular scenario, but it’s not surprising to find this general structure in a very large project.
So what happens when we introduce version conflicts?
The JVM can only load one version of a dependency at runtime. There are various ways to produce an executable artifact from SBT, and we can generally customize how they handle a version conflict. The default behavior is typically to pick the newest version of any given dependency and evict all others. This means if one dependency requires version 1.2.3 of library A and another dependency requires version 2.3.4 of library A, then only 2.3.4 will be available at runtime. We can run sbt evicted to see which versions are picked and which are evicted.
If the conflicting library versions are not binary compatible along a codepath called from our project, then we’ll find runtime exceptions like ClassNotFoundException or NoSuchMethodError. Sometimes we get lucky and we don’t actually call the binary-incompatible part of the library, but the only built-in way to verify this is to run the code.
Library authors generally try to avoid breaking binary compatibility, but it’s easy to overlook breaking changes. Even trivial changes like adding a default case class member or a default method parameter break binary compatibility.
Library authors also generally follow semver, meaning a breaking change results in a major version bump. Even if everyone follows semver perfectly, libraries evolve at different speeds. I’ve found myself in this scenario several times: we need a bug-fix or feature from the latest version of library A. We already use the latest version of library B, which depends on an older, binary-incompatible version of library A. The maintainers of B are nowhere to be found. We have a few options: Update A and risk runtime exceptions. Update B’s version of A, PR the change, and wait for the maintainers to merge and release the update. Update B’s version of A and release our own artifact internally, effectively a fork. None of these are particularly productive patterns.
In short, as we add dependencies, we inevitably end up with conflicting versions of transitive dependencies. If these conflicting versions are binary-incompatible, we’ll find ourselves debugging runtime exceptions.
To clear up any additional confusion, I recommend reading the official Scala documentation on Binary Compatibility for Library Authors, especially the section Why Binary Compatibility Matters.
Circular Dependencies
A circular dependency occurs when repo A depends on repo B and repo B depends on repo A.
In my experience, it’s rarely this simple. It’s more common to find several hops across multiple repos:

Again, an arrow from A to B means A depends on B.
SBT will prevent you from introducing circular dependencies within a single SBT project, but it has no way to prevent a circular dependency across SBT projects (i.e., across repos).
A more accurate representation is this:

From SBT’s perspective, v1 and v2 of repo A are distinct artifacts. It doesn’t know that they come from the same repo. However, it’s clearly an undesirable state. At some point we’ll need to make a breaking change in A and propagate the change through B, C, and D. Since D still depends on an older version of A, we’ll be forced to break B, C, and D along the way.
I’ve seen this several times when writing tests for utility code: we have a repo of common utilities at the root of the dependency graph. We write some tests and publish a new utility, but then encounter an issue in a downstream project caused by a bug in the utilities. We fix the bug and want to add some regression tests in the utilities project, but the bug involves some constructs from the downstream project. Instead of copying the code, we introduce a test dependency from the utility tests to the downstream project and write a nice regression test. SBT doesn’t prevent this, as its unaware of the broader dependency graph. Code-reviewers are happy to see more tests and overlook the dependency. We only discover the issue several months later when trying to update to a new version of some library used in the utilities and find runtime exceptions in the tests.
Long Dependency Chains
One natural side-effect of a poly-repo codebase is that changes in one repo require changes to other repos.
Many organizations have a project at the root of the dependency hierarchy called common or util. In several cases I’ve found myself working on a service with several library dependencies that depend on the util project. In other words, the util project is a transitive dependency, several times removed:

We reach for a construct from Util, but realize something about it is just slightly wrong. We have two choices. We can upstream a change to Util, make sure it works with A and B, and spend time updating and releasing the intermediate projects. Or we can re-implement a slight variation of the problematic construct and add an aspirational comment:
// TODO: move to util
It seems that the number of aspirational TODOs increases with the length of the dependency chain.
The Road to Sanity
Inspect Evictions
In a perfect world, sbt evicted would return nothing, meaning there are no version conflicts. In reality, this is virtually impossible. Even the most critical, carefully-maintained open-source libraries have evictions. There are some low-level, broadly-used libraries which will virtually always appear on this list (e.g., slf4j-api).
One of the simplest things we can do is to inspect the output of sbt evicted when adding or updating dependencies. When bumping a dependency to a newer version, we should compare the output from sbt evicted before and after to make sure there aren’t any new, binary-incompatible evictions.
Test, test, test
We can’t entirely eliminate version conflicts, and the Scala compiler also can’t help us detect problematic conflicts – instead, they manifest as runtime exceptions like NoSuchMethodError or ClassNotFoundException.
One of the simplest and most effective things we can do is to improve test coverage so that all important codepaths are regularly tested and runtime exceptions are found in CI. It’s really pretty simple: disciplined testing gives us the opportunity to crash and debug in CI rather than in production.
Reduce Dependencies
Scala has a relatively un-opinionated standard library (e.g., no standard JSON or CSV support). So we end up using a lot of libraries. There’s nothing inherently wrong with that, but we should be intentional about the dependencies we use.
When considering a dependency, we can evaluate three criteria:
- Is it really necessary? The simplest thing we can do is avoid carelessly introducing over-complicated dependencies. For example, breeze is a neat library, but has a non-trivial dependency footprint. So if we just need to compute summary statistics or do some basic vector arithmetic, we’re probably better off using built-in collection methods (
.sum, .length, .zip, .product, etc.) or using a zero-dependency alternative like Apache commons-math3. - Does the library have a reasonable number of dependencies? I usually bias towards small and focused libraries. It’s really just a numbers game. Each dependency has its own transitive dependencies, and each new dependency is a new opportunity for version conflicts.
- Do the authors regularly and thoughtfully update their dependencies? At the very least, the authors should release a new version for every major release of their dependencies.
A good example for the second and third criteria is elastic4s, a client and DSL for Elasticsearch. The library includes several sub-projects for using elastic4s with different effect systems (elastic4s-effect-cats, elastic4s-effect-monix, etc.), each published as a distinct artifact. The author also releases a new version for every version of Elasticsearch.
Carefully Structure Sub-projects
SBT allows us to define sub-projects within a larger project, and each sub-project is published as a distinct artifact.
When building projects that are published and consumed by downstream users, we should structure them thoughtully, and in particular avoid grouping many unrelated dependencies in a single project.
For example, we might have a fairly large utils project with, among others, utilities for consuming data from Amazon S3 and utilities for working with JSON data. The S3 utilities depend on the S3 Java SDK, and the JSON utilties depend on circe. We should split the project into two SBT sub-projects, published as distinct artifacts. S3 users need only depend on the S3 artifact and its dependencies. JSON users only need the JSON artifact and its dependencies. By defining this separation, we decrease the chance of dependency conflict for both sets of users. Users working with S3 and JSON can just use both of the artifacts.
This is a pattern used by many libraries. For example, AWS publishes over 300 Java SDKs, delineated by their cloud services. Lightbend’s alpakka project includes over 40 sub-projects for using akka and akka streams with various datastores.
The main advantage of having small, focused sub-projects is that it decreases the opportunity for version conflicts in downstream projects. Remember, it’s a numbers game. It also decreases the time spent downloading artifacts in CI and the size of artifacts published from downstream projects which use our artifacts.
It might seem tedious to carefully define sub-projects and tempting to clump everything together. I’ve found the effort is a one-time investment, and we reap the rewards for the lifetime of the project.
Pin Standard Versions Across Your Organization
An organization typically arrives at some defacto official libraries – maybe akka-http for web services and cats-effect for IO.
Beyond picking standard libraries, we should also agree on standard versions of these libraries.
For example, we agree to use akka-http 10.1.12. When 10.2.0 comes out, we carefully examine the changelog, test it out on branches in several important projects, and only then promote it as the new official version. This diligence serves to prevent upgrading a version of a widely-used dependency in one project, only to introduce a binary-incompatibility with other projects.
We can go a step further and enumerate the standard versions in an internally-published SBT plugin. This allows users to forget about specific library versions in favor of simpler syntax like:
libraryDependencies ++= Seq(
StandardLibraries.akkaHttp,
StandardLibraries.catsEffect,
...
)
This pattern ensures that the standard versions are defined in code rather than some random wiki. Versions are promoted via code-reviewed PRs, and we can even write plugin tests to catch new evictions caused by upgrading a standard version. Users can forget about bumping a bunch of library versions and instead just make sure they’re using the latest version of the plugin.
As an aside, I find it extremely useful to have an internal plugin that abstracts away the common SBT boilerplate for loading credentials, running linters, releasing, etc.
Prune Unused Dependencies
When we include a dependency, that dependency becomes available to downstream users of our published artifacts and can cause dependency conflicts in their projects. Even if it doesn’t cause a conflict, it gives an opportunity to start using the dependency transitively, only to find a broken build once we remove the unused dependency from the original project.
As such, we should regularly prune unused dependencies, especially in projects which are published as libraries.
The wonderful sbt-explicit-dependencies plugin already includes two tasks for pruning unused dependencies:
unusedCompileDependenciesprints a list of the unused dependenciesunusedCompileDependenciesTestthrows an exception if there are any unused dependencies
Unfortunately there are some subtle edge cases to be aware of. For example, some very common logging libraries (e.g., logback-classic) are loaded exclusively at runtime. So the unusedCompileDependencies task will mark logback-classic as an unused dependency. The solution is to either add these dependencies with a % Runtime modifier or tune the unusedCompileDependenciesFilter configuration.
Prune Redundant Transitive Dependencies
This tip is subtle and still up for debate in my own mind. Anyone who finds it confusing can safely skip it.
A redundant transitive dependency occurs when we declare dependencies A and B, where B already depends on A. We already get A by depending on B, so we don’t need to declare it explicitly. In this case, A is a redundant transitive dependency
For example, circe already depends on cats-core. So if we declare both circe and cats-core in our libraryDependencies, cats-core is a redundant transitive dependency.
Why should we avoid redundant transitive dependencies? It prevents us from accidentally updating the redundant transitive dependency without updating the dependency that originally brought it in. For example, if we declare both circe and cats-core and later see a new release of cats-core, we might update cats-core without updating circe. This evicts the version of cats-core expected by circe and can introduce a binary incompatibility.
There’s also a pretty simple argument against this tactic: if we only declare circe, start heavily using cats-core, and for whatever reason stop using circe, then circe technically becomes an unused dependency. And I previously suggested we avoid unused dependencies.
On this topic, the sbt-explicit-dependencies plugin includes a couple tasks designed for the opposite of what I recommend:
undeclaredCompileDependenciesprints a list of dependencies used to compile which are not explicitly declaredundeclaredCompileDependenciesTestthrows an exception if there are any dependencies used to compile but not explicitly declared
In my experience it can be quite shocking (even JARring) to see all of dependencies used in a large project. I find explicitly enumerating them all adds little value, is tedious to maintain, and increases the chance that someone introduces a binary incompatibility by updating one of them.
Scala Steward
Scala Steward, in the authors’ words, is “a bot that helps you keep your scala projects up-to-date.” It works by cloning an SBT project, checking for new versions of its dependencies, and creating a branch and PR for each out-of-date dependency.
Here’s a Scala Steward PR to update akka-actor and akka-stream in the elastic4s repo.
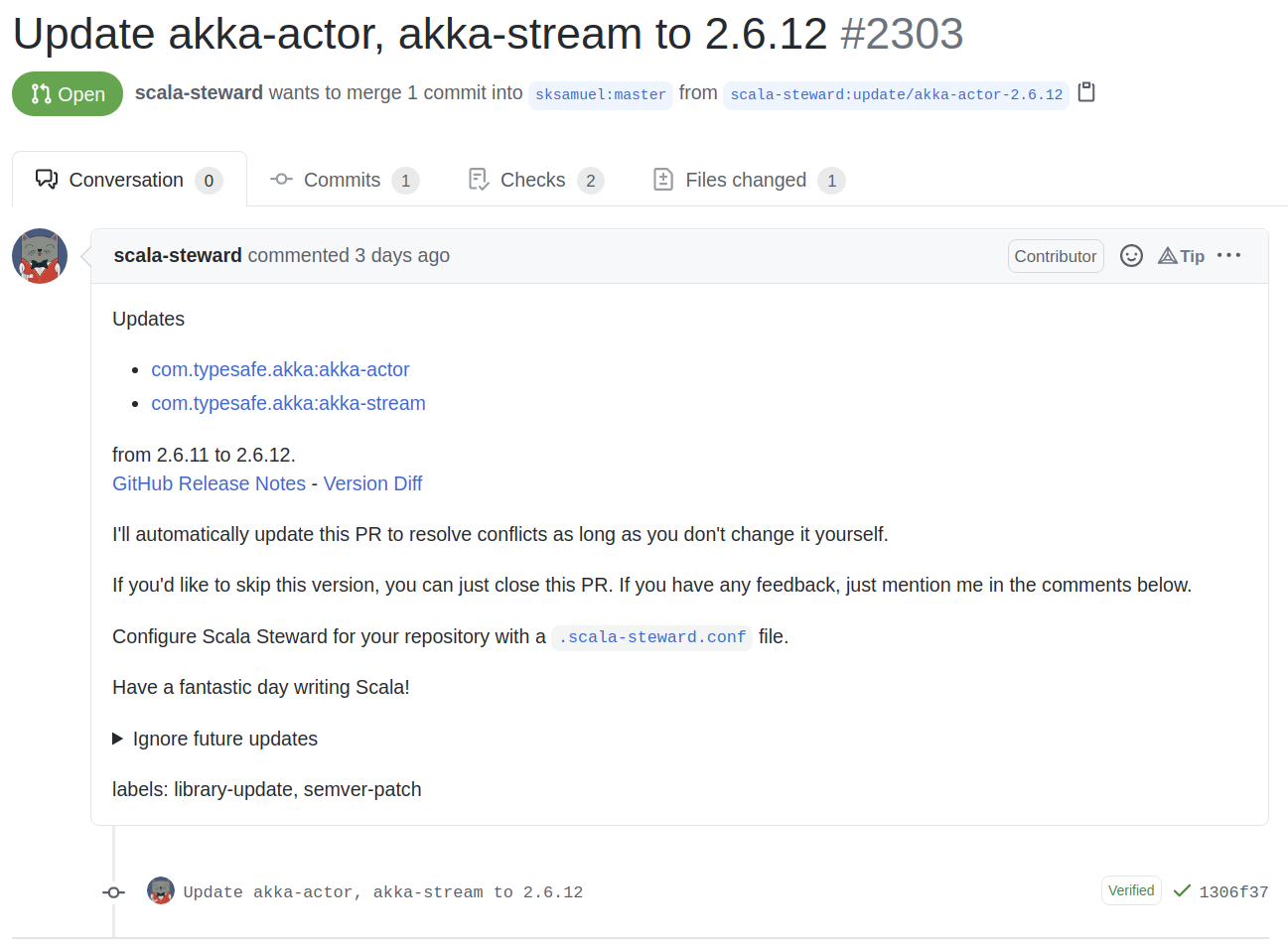
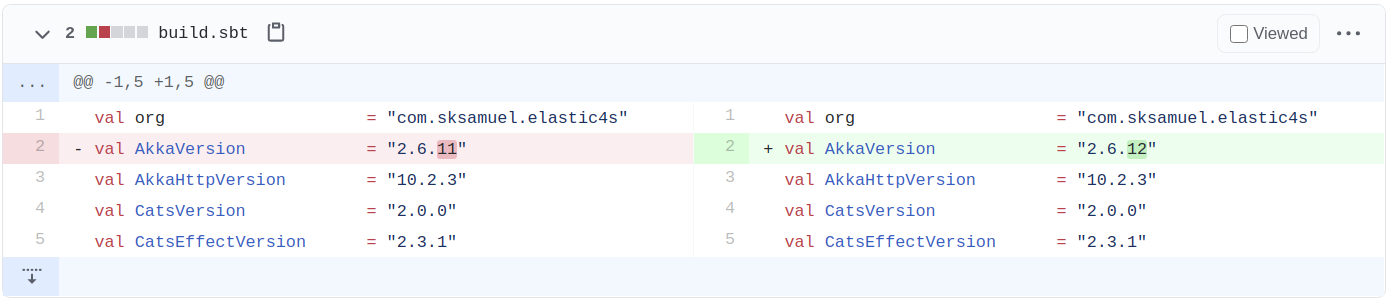
It actually re-writes source code, which is impressive considering there are several ways to define dependencies in SBT.
Scala Steward runs for free on open-source repos and we can use the Scala Steward docker image to run it on internal infrastructure for private repos.
In the past I’ve used it by setting up a weekly Scala Steward cronjob for each internal repo. This seemed like an obvious win at first. Nobody wants to spend time checking for new versions and baby-sitting version bump PRs – let a bot do it.
I learned there are some pitfalls if not rolled out carefully.
The main issue is that repos are maintained at different cadences, and introducing Scala Steward to a fleet of diverse but dependent repos will lead to version conflicts. Organizations usually have some actively-maintained repos with snappy and robust CI. They also have some barely-maintained legacy repos with insufficient or flaky CI. When an active repo starts merging and releasing dependency updates, and a legacy repo doesn’t, we end up with dependency conflicts when the two repos’ artifacts are combined in a third downstream repo.
I found the best way to use Scala Steward is to first create an internal SBT plugin which enumerates standard versions of libraries used across the organization. I elaborated on the exact design of this above. The gist of it is that we should only be updating versions of broadly-used external libraries in one place, and we should coordinate these updates among teams and repo maintainers. Ideally we arrive at a steady-state where Scala Steward only updates internal dependencies and rarely-used external dependencies. Unless all of our repos have uniform maintenance and release cycles, setting Scala Steward loose to update all dependencies can get ugly.
An SBT Wishlist
Finally, here are some dependency management features I’d like to see in SBT or an SBT plugin.
Detect Circular Dependencies
This feature would detect circular dependencies across repos, addressing the issues in the circular dependencies section.
One possible implementation: provide a task called circularTest. It grabs the organization and project name, walks the project’s dependency graph, and throws an exception if it finds any artifacts with the same organization and name. I think it’s safe to assume another artifact with the same organization and name is simply an older version of the current project. We would execute this task in CI.
Note that this doesn’t actually prevent the introduction of a circular dependency – it simply detects that one exists. In order to truly prevent circular dependencies, the SBT project would have to know about the projects which depend on it. This would require maintaining an aggregate view of the dependency graph, external to any single project.
Disallow Evictions by Default
This feature would disallow all evictions (version conflicts) by default, except for a user-provided list of permitted evictions.
One possible implementation: provide a task called evictedTest, which uses the existing evicted task to find all evictions, checks them against a list of permitted evictions defined in the project’s settings, and throws an exception if a new eviction is found. We would execute this task in CI.
Perhaps there’s also a way to use Mima to check specifically for binary-incompatible evictions?
Similar to circularTest, this doesn’t actually prevent version conflicts. It simply forces us to explicitly define them, so that we know what we’re getting into before merging and releasing a dependency update.
Appendix
Further Reading
- Better Management of Transitive Dependencies and Conflicts
- Binary Compatibility for Library Authors
- Mima (Migration Manager) – an SBT plugin that checks binary compatibility of the current artifact against older ones. I haven’t used it myself, but hope to try it soon.
- Pipe Dream: Coursier Solve – this is more of a free-form discussion, but I learned a lot from the comments.
What about mono-repos?
I’ve worked in some big repos, but never an intentional mono-repo. It can be a controversial topic, but all merits aside, I think it’s much more natural for an organization to expand horizontally across repos, rather than vertically within a single repo. I also don’t think Github, Gitlab, Bitbucket, et. al. offer many features that truly support or encourage a mono-repo. In fact it seems that features like Github’s repository templates actively encourage repo proliferation.
I’d like to find some time to explore newer build tools like Pants and Bazel, which seem to facilitate mono-repo development. I really hope that the smart folks at Google, Facebook, Twitter, Microsoft, etc. moved to mono-repos at least partially because they solve a lot of the dependency-related issues I covered.
Finding Dependency Versions
To find the exact versions of a library’s dependencies, just find the library on search.maven.org (e.g., akka-grpc), and you’ll see an XML section containing the exact dependencies and versions:
<dependencies>
...
<dependency>
<groupId>io.grpc</groupId>
<artifactId>grpc-core</artifactId>
<version>1.32.1</version>
</dependency>
...
</dependencies>