
Are Postgres functions faster than queries? (a very simple benchmark)
Introduction
In my work with Postgres and other databases, I’ve often heard the statement “stored procedures (i.e., functions in Postgres) are faster than queries.”
To be precise, “stored procedure” refers to a Postgres function, defined using the create function command, and executed by passing a string like select * from some_function(...) from the client to the database server.
“Query” refers to a standard SQL query (e.g., select * from some_table where id = 10), defined by the client, and executed by passing the literal query string from the client to the database server.
I’m willing to accept that a function is faster than a query if the function avoids passing intermediate results back to the client. There’s an obvious cost to sending bytes over the network, so, all else equal, a function that keeps intermediate results in the database is going to execute faster than multiple queries that pass intermediate results to the client.
However, that’s not really what I’m after. I’m more interesting in answering this question:
Assuming the function and query are executing the same underlying statements and passing the same data back to the client, is the function faster than the query?
In this post, I take a first pass at answering this question based on a very simple benchmark.
Expand for the spoiler!
On this benchmark, the difference between Postgres functions and queries is negligible. I.e., the answer to the title is: not really.The Benchmark
All the benchmarking code is available in my site-projects repo, but here’s a quick summary.
Database Schema
I created a small blog-style database with two tables for posts and comments.
create table post (
post_id serial primary key,
post_uuid uuid unique not null,
contents text not null,
created_at timestamp not null,
updated_at timestamp
);
create table comment (
comment_id serial primary key,
comment_uuid uuid unique not null,
post_id serial references post(post_id),
contents text not null,
created_at timestamp not null,
updated_at timestamp
);
create index comment_post_id_idx on comment(post_id);
I populated the database with 100,000 random posts and 1,000,000 random comments (exactly 10 comments per post).
For the comparison, I wrote a function and query to count the number of comments for a given post_uuid:
create function comment_count_by_post_uuid(uuid)
returns integer
language sql
parallel safe
returns null on null input
as $$
select count(comment_id)
from comment c
join post p on c.post_id = p.post_id
where p.post_uuid = $1
$$;
select count(comment_id)
from comment c
join post p on c.post_id = p.post_id
where p.post_uuid = %s::uuid
Benchmarking Scripts
To execute the functions and queries, I wrote a Python script that does the following:
- Connects to Postgres using the
psycopg2client library. - Selects all the post UUIDs, sorts them, and keeps them in memory.
- If called with arg
function, loops over the post UUIDs and runs the function on each UUID. - If called with arg
query, loops over the post UUIDs and runs the query on each UUID.
I incorporated this Python script in a bash script that does the following:
- Starts the Postgres container and runs migrations to create tables and insert random data.
- Re-starts the container to reset metrics.
- Starts recording container metrics from
docker stats. - Runs the query benchmark.
- Re-starts the container to reset metrics.
- Starts recording container metrics from
docker stats. - Runs the function benchmark.
- Shuts down the containers.
- Plots the results.
Environment
I ran Postgres 15.1.0 in a Docker container on my 2018 Intel i7 Mac Mini.
I used a combination of docker-compose and Postgres configurations to limit the resources: 1 CPU, 8GB memory reservation, 8GB memory limit, and shared_buffers set to 4096MB.
I ran the benchmarking script on the same Mac Mini to eliminate variability from a network connection.
Analysis
To analyze the execution time, I simply used the time command.
To analyze database resource usage, I wrote a simple bash script that polls the docker stats command and exports the following metrics:
- Container CPU usage (%)
- Container memory usage (MiB)
- Network in (MB)
- Network out (MB)
Why would the function be faster?
Before we get into the results, let’s speculate a bit: if the function and query are doing the same thing, and returning the same data, why would the function be faster?
A few possible reasons come to mind for me:
select * from comment_count_by_post_uuid(...)is a shorter string than the equivalent SQL query, so by calling the function, we’re sending fewer bytes over the network. Perhaps this is enough to give the function an edge?- Perhaps the function lets Postgres avoid repeatedly parsing the underlying query?
- Perhaps the function lets Postgres cache the query plan, and therefore skip query planning?
We’ll see if any of these hold up.
Results
The execution times for 100,000 iterations are about 1 minute and 35 seconds for both the function and the query, or about 1050 iterations per second.
The container metrics are plotted below:
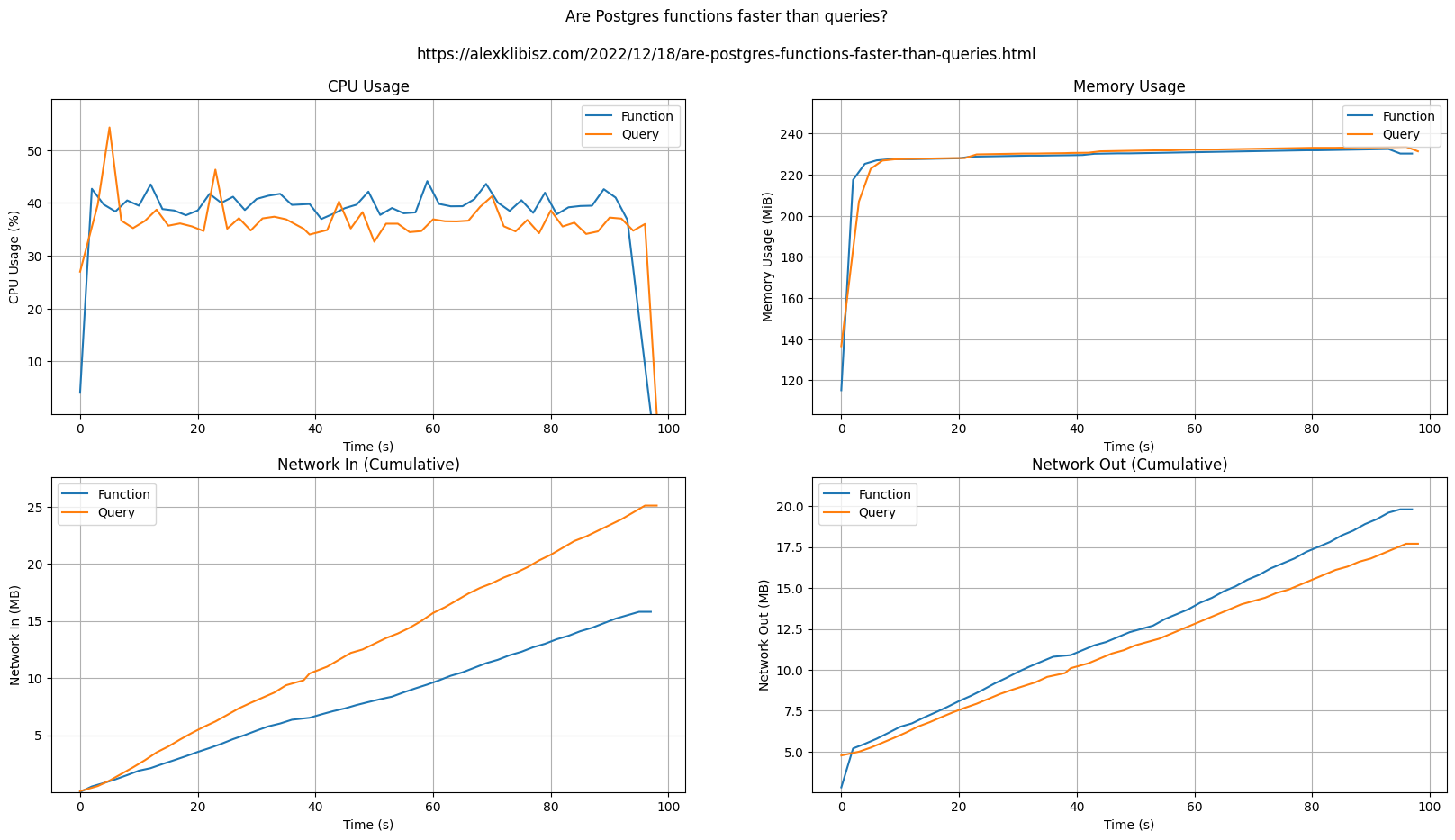
Execution time and memory usage are indistinguishable.
The query seems to use slightly less CPU compared to the function. I’m not sure why this would be the case, but it happens consistently.
Network input is consistently higher for the query. This makes sense, as we’re sending a larger string over the network to the database.
Network output is consistently very slightly higher for the function. I’m not sure why this would be the case, but it happens consistently.
I ran this several times and also swapped the order (function first, then query, and vice-versa). The only difference I observed was the execution times moving a couple seconds in either direction. Otherwise, everything remains as described above.
Interpretation
Based on these results, for the simple select query that I benchmarked, functions are neither obviously better nor worse than queries.
Functions have a slight advantage in lower network usage. Queries might have a slight advantage in lower CPU usage.
In cases like this, my tie-breaker tends to be maintainability. With the toolchains I’ve used, queries are typically easier to maintain and evolve than functions. Changing a function generally requires both a database migration and application deployment, whereas changing a query generally only requires an application deployment.
Note, this is by no means a definitive conclusion! I can think of several scenarios where I would still consider both a function and a query. But, for a simple select query like the one I benchmarked, I will probably reach for a query over a function.